Of Faults and Favorites: Model Checking a Pagination Algorithm with Alloy
Using Alloy 6 to formally verify a pagination algorithm that merges favorited and unfavorited event lists.
This article is a literate Alloy 6 model. Download of-faults-and-favorites.md and run alloy6 exec of-faults-and-favorites.md to verify the results yourself.
Preamble: My Background With Model Checkers
I first encountered property testing through PropEr in the Elixir world, and it felt like a superpower. Generate thousands of tests, exercise the bounds of your inputs, verify that properties hold. A lazy programmer's dream.
Model checking takes this further: rather than testing many random cases, you verify that invariants hold across the entire state space.
Back in 2022, I took a short TLA+ training course at the penultimate Strange Loop conference and have wanted to use model checking on a real problem ever since.
Though model checking would have helped many times, I always chose to ship features instead — the gap between knowing what model checkers do and writing an effective model was too wide for any single deadline.
Recently, I ran into a problem at work that seemed like a candidate for model checking. I began drawing all the possible states and realized I didn't trust myself to cover every possible scenario. That's when I remembered that model checking is perfect for this.
With Claude 4.6 Opus available, formal model checking for the algorithms that warrant it has become much more tenable. I built this exploration with Claude. I brought the problem and the domain knowledge, the requirements and properties of the system, and used Claude to generate the Alloy syntax and work through the properties.
LLMs handle the Alloy syntax well. An Alloy expert could improve these specifications, but the output is accurate enough for this problem.
The rest of this article covers the problem, the algorithm, and two competing implementations - one with bugs, and one correct.
Table of Contents
What is Model Checking?
We verify software by testing it. Unit tests, integration tests, maybe property-based tests — pick some inputs, check that outputs match expectations. This works, but it has a fundamental limitation: we can only check the cases we think to write. If a pagination bug only surfaces with three events on the same day where one is favorited, we'd better hope someone writes that exact test.
Model checking inverts this. We describe the rules of our system and the properties we want to hold, and the model checker exhaustively searches for violations. If it finds one, it gives us a concrete counterexample. If it doesn't, we know the property holds across every scenario it explored.
We have two flavors:
| Technique | What it proves | Limitation |
|---|---|---|
| Bounded model checking | Property holds for all states reachable within N steps | Only covers traces up to length N |
| Inductive proof | Property holds for all reachable states, period | Requires a strong enough invariant |
The inductive approach is the interesting one. It works like mathematical induction: prove the property holds initially (base case), prove that if it holds in state S it still holds after any transition to S' (inductive step), and you've proven it for all reachable states regardless of trace length. No bounds, no caveats.
Why Alloy?
I chose Alloy 6 for this work. A few reasons:
- Readability. Alloy's syntax is closer to set theory and predicate logic than TLA+'s ASCII notation. The specifications read almost like mathematical statements.
- Temporal operators. Alloy 6 added
always,eventually,after, andbeforeoperators for reasoning about state over time, which is exactly what pagination needs. - Counterexamples. When a check fails, Alloy gives you a concrete scenario you can step through: not just "your property is violated" but "here is exactly the state sequence that breaks it."
- Literate markdown. Alloy can execute code blocks inside markdown files. This article is itself an executable specification. Let's start with the Alloy header:
module Pagination
open util/ordering[Day]
open util/ordering[Event] as eventOrdA brief glossary of Alloy syntax used throughout this article:
| Keyword | Meaning |
|---|---|
sig | Declares a type (like a class or struct) |
one sig | A singleton — exactly one instance exists |
var sig X in Y | A mutable subset of Y that can change over time |
fun | Defines a function that returns a value |
pred | Defines a predicate (boolean constraint) |
fact | A constraint that always holds (an axiom) |
assert / check | A property to verify — Alloy searches for counterexamples |
lone | Zero or one (like Option or nullable) |
# | Set cardinality (count of elements) |
<=> | If and only if (biconditional) |
My first attempt at this was with Stateright in Rust. Stateright is a model checker, so it exhaustively explores the entire state space. With Stateright I could cover more of the state space than Alloy allows (up to 12 events rather than 5) in a reasonable amount of time. Alloy's inductive proofs are the decisive advantage: with some insight into the model structure, I can mathematically prove the algorithm correct rather than merely test it at scale.
The Problem
Personalization complicates everything!
We are looking to present a list of upcoming events with a specific ordering. Events must be returned chronologically with the exception that events that a user has "favorited" sort before "non-favorited" events on the same calendar day.
| Event | Day | Favorited |
|---|---|---|
| E1 | 0 | ✓ |
| E2 | 0 | |
| E3 | 1 | |
| E4 | 1 | ✓ |
| E5 | 3 |
The combined list sorts as follows:
E1*, E2, E4*, E3, E5, ...When you have the entire dataset of events and favorites in memory, this operation is trivial. In fact, it would be equally straightforward if you could ensure that you have the complete data for any given day. In our situation though, the events come to us paginated from two different sources and the pages don't line up with day boundaries. This is where the "fun" begins and why I'm doing this deep dive.
We receive:
A list of the upcoming favorited events sorted chronologically
-and-
A list of all events, including the favorites, sorted chronologically - but the favorites are not identified in this list (AllEvents below)
-or-
A list of all events with the favorites filtered out, sorted chronologically (ExcludeFavorites below)
The question: how do we construct the combined list when the combined list is fetched in pages and the sources are paginated?
Helpers
Before we dive into the proof, these predicates and functions help us build a little library of ordering rules and shared infrastructure for both implementations.
Day and Event Ordering
pred dayBefore[earlierDay, laterDay: Day] {
lt[earlierDay, laterDay]
}
pred chronoBefore[earlierEvent, laterEvent: Event] {
eventOrd/lt[earlierEvent, laterEvent]
}Merge Ordering
The desired ordering for the final output is: earlier days first, favorites before non-favorites within the same day, and chronological within the same day and favorite status.
The pagination algorithm doesn't have global knowledge of which events are favorited. It only knows an event is favorited if it appeared in the favorites list candidates for the current page. Events sourced from the standard list are treated as non-favorited for merge ordering, even if they are globally favorited.
mergeOrderBefore takes a knownFavorites parameter — the set of events sourced from the favorites list — and uses that instead of global Favorited membership.
pred mergeOrderBefore[firstEvent, secondEvent: Event, knownFavorites: set Event] {
dayBefore[firstEvent.day, secondEvent.day]
or (firstEvent.day = secondEvent.day and firstEvent in knownFavorites and secondEvent not in knownFavorites)
or (firstEvent.day = secondEvent.day and
((firstEvent in knownFavorites) <=> (secondEvent in knownFavorites)) and
eventOrd/lt[firstEvent, secondEvent])
}The Favorited List
Both implementations share the same favorited list: a mapping from position to event, built by counting how many other favorites precede each one chronologically.
fun favList: Int -> Event {
{ position: Int, currentEvent: Favorited |
position = #{otherEvent: Favorited | chronoBefore[otherEvent, currentEvent]} and
position >= 0 and position < #Favorited
}
}State
The algorithm maintains mutable state: which events have been emitted so far, what was emitted on the last page (for detecting duplicates), and cursor positions into each list.
var sig PriorEmitted in Event {}
var sig LastPageOutput in Event {}
one sig Tokens {
var stdTok: lone Int,
var favTok: lone Int
}
fact TokenBounds {
always (
(some Tokens.stdTok implies Tokens.stdTok >= 0) and
(some Tokens.favTok implies Tokens.favTok >= 0)
)
}For visualization, we derive each event's lifecycle state from PriorEmitted and LastPageOutput. This doesn't affect the algorithm or proofs — it gives the Alloy visualizer a single readable label per event that changes as the trace progresses.
enum EmitState { Upcoming, CurrentPage, Historical, Duplicate }
fun emitState: Event -> EmitState {
{ e: Event, s: EmitState |
(s = Duplicate and e in LastPageOutput and before (e in PriorEmitted)) or
(s = CurrentPage and e in LastPageOutput and not before (e in PriorEmitted)) or
(s = Historical and e in PriorEmitted - LastPageOutput) or
(s = Upcoming and e not in PriorEmitted)
}
}Token Advancement
After emitting a page, we advance each token past contiguous emitted events. "Contiguous" is doing real work here: the algorithm walks forward through emitted positions and stops at the first gap. If position 0 is emitted, position 1 is not, and position 2 is emitted, the token stops at 1.
fun advanceToken[sourceList: Int -> Event, token: lone Int, emittedEvents: set Event]: lone Int {
no token => none
else
let gap = min[{position: Int | position >= token and some sourceList[position] and sourceList[position] not in emittedEvents}] |
some gap => gap
else none
}In plain terms: starting from the current token position, find the first un-emitted event in the list. If there is one, that becomes the new token. If every remaining event has been emitted, the token becomes none (end of list).
Stutter
A stutter transition lets the system idle without loading a new page, standard in temporal models to avoid forcing progress at every step. We clear LastPageOutput since no page was loaded.
pred stutter[] {
PriorEmitted' = PriorEmitted
no LastPageOutput'
Tokens.stdTok' = Tokens.stdTok
Tokens.favTok' = Tokens.favTok
}The Domain Model
Events occur on a specific day. We use a global event ordering (via util/ordering[Event]) that is consistent with day ordering: all events on an earlier day precede all events on a later day. This means Event$0 is always the chronologically earliest event, Event$1 is next, and so on — making counterexample traces readable.
sig Day {}
sig Event {
day: one Day
}
fact EventOrdering {
all disj e1, e2: Event | dayBefore[e1.day, e2.day] implies chronoBefore[e1, e2]
}Some events are favorited. For run commands we require at least 3 events and at least one favorite to produce interesting scenarios, but check commands omit this constraint so the proofs cover the full state space — including edge cases like no favorites or few events.
sig Favorited in Event {}
pred interestingScenarios[] {
#Event >= 3
some Favorited
Config.pageSize = 2
}Assumptions
A few simplifications:
- Tokens are cursors. Each source list has an integer cursor (token) tracking position.
nonemeans end-of-list. - No concurrent mutations. The event data doesn't change while we're paginating.
- Chronological ordering. Events are totally ordered: first by day, then by position within the same day. The global event ordering is constrained to be consistent with day ordering.
one sig Config {
pageSize: one Int
}
fact PageSizeBounds {
Config.pageSize >= 1
Config.pageSize <= #Event
}Observable Properties
These describe the output behavior we care about, independent of implementation internals.
No Duplicates
No event should appear on more than one page. Since PriorEmitted is a set, it can't contain duplicates by construction — adding an event that's already present is a no-op. We detect duplicates instead by tracking LastPageOutput separately and using the temporal before operator to check whether an event in the current page was already in PriorEmitted in the previous state. This check appears in the NoDuplicates assertions rather than as a predicate here.
Duplicate prevention in the inductive proofs comes from the structural invariants (tokens past emitted + contiguity), which prevent loadMore from selecting already-emitted events in the first place.
Ordering
Within each day, favorites should come before non-favorites. Within the same favorite status, events should be in chronological order.
pred favoritesFirstWithinDay[] {
all favoritedEvent: Favorited, nonFavoritedEvent: Event - Favorited |
favoritedEvent.day = nonFavoritedEvent.day and nonFavoritedEvent in PriorEmitted
implies favoritedEvent in PriorEmitted
}
pred favoritesChronological[] {
all earlierEvent, laterEvent: Favorited |
earlierEvent.day = laterEvent.day and laterEvent in PriorEmitted and eventOrd/lt[earlierEvent, laterEvent]
implies earlierEvent in PriorEmitted
}
pred nonFavoritesChronological[] {
all earlierEvent, laterEvent: Event - Favorited |
earlierEvent.day = laterEvent.day and laterEvent in PriorEmitted and eventOrd/lt[earlierEvent, laterEvent]
implies earlierEvent in PriorEmitted
}
pred orderingInvariant[] {
favoritesFirstWithinDay[] and
favoritesChronological[] and
nonFavoritesChronological[]
}Inductive Properties
The property we care about (no duplicates) is not inductive by itself. Knowing there are no duplicates in state S doesn't give us enough to prove there won't be duplicates after a transition to S'. We need more context about internal state.
To make the proof work, we strengthen the invariant with two auxiliary properties:
- Tokens point past emitted events. If a token is at position
P, every event beforePhas been emitted. When a token is exhausted (none), all events in that list have been emitted. The exhausted case matters: without it, the invariant is vacuously true fornonetokens, and the solver can construct unreachable states where a list appears exhausted but events remain unemitted. - Emitted events are contiguous. Within each source list, emitted events form a contiguous prefix with no gaps.
These are internal to the algorithm, not things we'd show a user. But contiguity guarantees the token advancement logic can't re-fetch an already-emitted event, which is what prevents duplicates.
To prove ordering (favorites before non-favorites within each day), we further strengthen the invariant by including orderingInvariant. The token and contiguity properties provide enough context for ordering to be inductive: when a non-favorite on day D is emitted, all favorites on day D are either already emitted (positions before the token) or in the current candidate set (where merge ordering places them first).
We use the exact same strengthened invariant for both implementations. The only difference is which standard list we plug in. One maintains the invariant. The other can't.
Inductive properties were an important area where LLMs helped. The observable properties are, at least in this case, clear and direct to implement. We understand the operations that can happen and know what we want to be true at the end.
By contrast, inductive properties are harder to see and took more work to figure out. By using Claude, I was able to go back and forth and explore the problem, stepping through different states until I found inductive properties that made sense.
pred tokensPointPastEmittedGeneric[stdList: Int -> Event] {
some Tokens.stdTok implies
all position: Int | position >= 0 and position < Tokens.stdTok implies
(some stdList[position] implies stdList[position] in PriorEmitted)
no Tokens.stdTok implies
all position: Int | position >= 0 implies
(some stdList[position] implies stdList[position] in PriorEmitted)
some Tokens.favTok implies
all position: Int | position >= 0 and position < Tokens.favTok implies
(some favList[position] implies favList[position] in PriorEmitted)
no Tokens.favTok implies
all position: Int | position >= 0 implies
(some favList[position] implies favList[position] in PriorEmitted)
}
pred emittedAreContiguousGeneric[stdList: Int -> Event] {
all earlierPosition, laterPosition: Int |
earlierPosition < laterPosition and
some stdList[laterPosition] and
stdList[laterPosition] in PriorEmitted
implies
(some stdList[earlierPosition] implies stdList[earlierPosition] in PriorEmitted)
all earlierPosition, laterPosition: Int |
earlierPosition < laterPosition and
some favList[laterPosition] and
favList[laterPosition] in PriorEmitted
implies
(some favList[earlierPosition] implies favList[earlierPosition] in PriorEmitted)
}
pred inductiveInvariantGeneric[stdList: Int -> Event] {
tokensPointPastEmittedGeneric[stdList] and
emittedAreContiguousGeneric[stdList]
}
pred inductiveInvariantWithOrderingGeneric[stdList: Int -> Event] {
inductiveInvariantGeneric[stdList] and
orderingInvariant[]
}Implementation A: AllEvents
The first approach includes all events in the standard list regardless of favorite status. Since the favorited list contains only favorites, favorites appear in both lists.
This was the approach we hoped to take. It had one known flaw: since events sort favorites first within each day, the favorites cursor could advance further into the future than non-favorites. For example:
| Events Page 1 | Favorites Page 1 |
|---|---|
| E1 (Day1) | E1 (Day1) |
| E2 (Day1) | E8 (Day3) |
| E3 (Day1) | E9 (Day4) |
| E4 (Day2) | |
| E5 (Day2) |
The combined list would look like this:
┌──Day 1──┐┌Day 2┐┌D3┐ D4
E1, E2, E3, E4, E5, E8, E9What's missing are the events from the 2nd page of the "Event Page", E6 and E7 which occur after E5 and also on Day2. These would appear when the next page loads. This was a trade-off we were comfortable with. But the proof found a more sinister issue.
We accepted this trade-off. The proof found a worse problem.
fun stdListAllEvents: Int -> Event {
{ position: Int, currentEvent: Event |
position = #{otherEvent: Event | chronoBefore[otherEvent, currentEvent]} and
position >= 0 and position < #Event
}
}
fun pageOutputAllEvents[stdToken, favToken: lone Int]: set Event {
let stdCandidates = (no stdToken) => none
else stdListAllEvents[{position: Int | position >= stdToken}],
favCandidates = (no favToken) => none
else favList[{position: Int | position >= favToken}],
candidates = stdCandidates + favCandidates |
{ event: candidates | #{otherEvent: candidates | mergeOrderBefore[otherEvent, event, favCandidates]} < Config.pageSize }
}
pred loadMoreAllEvents[] {
let pageOutput = pageOutputAllEvents[Tokens.stdTok, Tokens.favTok] {
some pageOutput
PriorEmitted' = PriorEmitted + pageOutput
LastPageOutput' = pageOutput
Tokens.stdTok' = advanceToken[stdListAllEvents, Tokens.stdTok, pageOutput]
Tokens.favTok' = advanceToken[favList, Tokens.favTok, pageOutput]
}
}
pred initAllEvents[] {
no PriorEmitted
no LastPageOutput
Tokens.stdTok = 0
Tokens.favTok = 0
}
pred traceAllEvents[] {
initAllEvents[]
always (loadMoreAllEvents[] or stutter[])
}
pred inductiveInvariantAllEvents[] {
inductiveInvariantGeneric[stdListAllEvents]
}
pred inductiveInvariantWithOrderingAllEvents[] {
inductiveInvariantWithOrderingGeneric[stdListAllEvents]
}The set comprehension on the last line of pageOutputAllEvents selects events from the candidate pool where fewer than pageSize other candidates precede them in merge order — effectively, the first pageSize events.
Why It Breaks
The overlap between the two lists creates gaps. Consider three events: E0 on Day0, E1 on Day1 (not favorited), and E2 on Day1 (favorited).
stdListAllEvents: [0→E0, 1→E1, 2→E2]
favList: [0→E2]On the first page, the algorithm emits E0 and E2 (E2 comes before E1 because favorites come first within a day). The token advancement for the standard list walks forward from position 0: position 0 (E0) is emitted, advance. Position 1 (E1) is not emitted. Stop. The standard token is now at position 1.
Position 2 (E2) is also emitted. There's a gap. On the next page load, the algorithm fetches candidates from position 1 onward: {E1, E2}. E2 gets emitted again. Duplicate.
The contiguity invariant catches this: after the first page, position 2 is emitted but position 1 is not. The invariant breaks at state 1, and the duplicate materializes at state 2.
Visualization
Alloy provides a handy visualizer when running it as a GUI. Using it on the run AllEvents_DuplicateTrace step (described below) we can see an example of the failure.
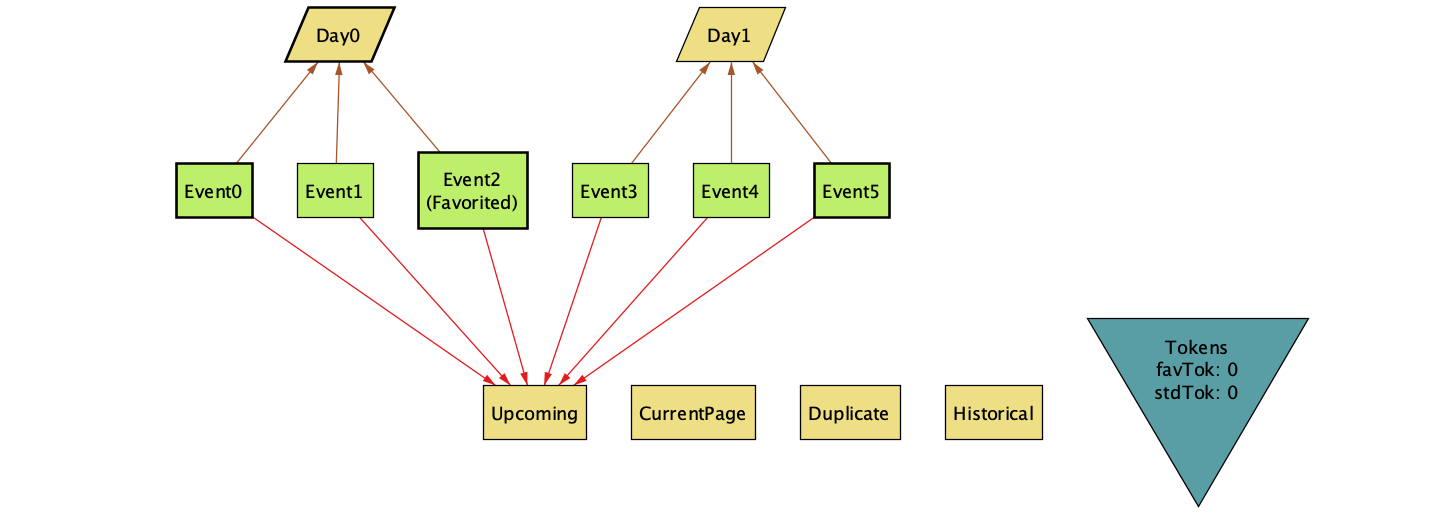
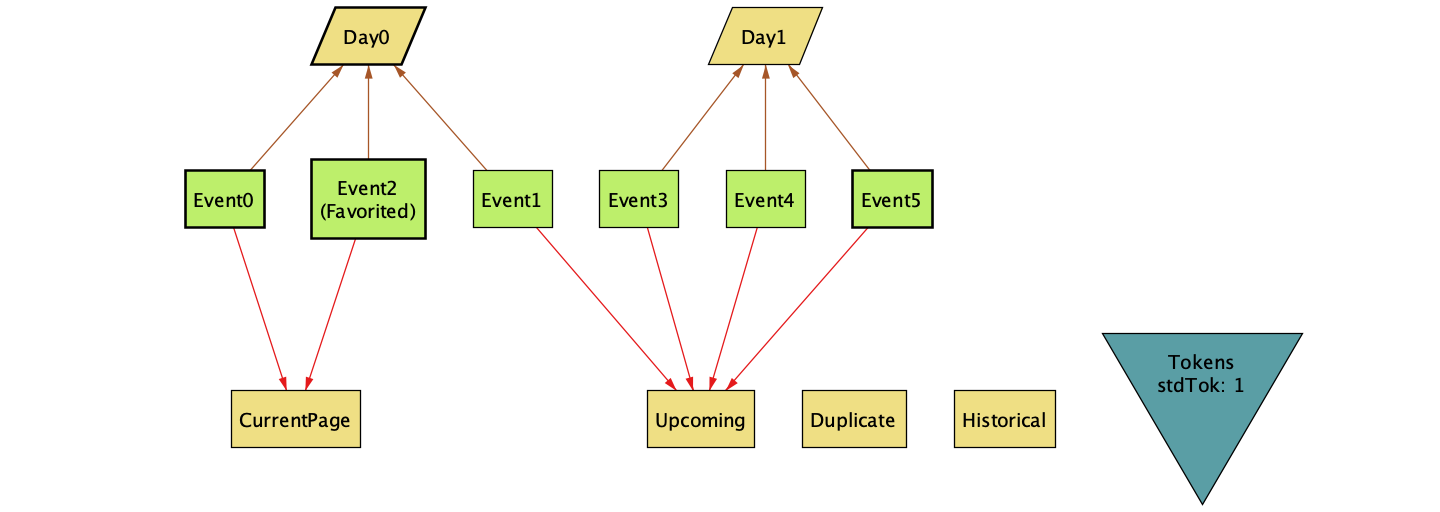
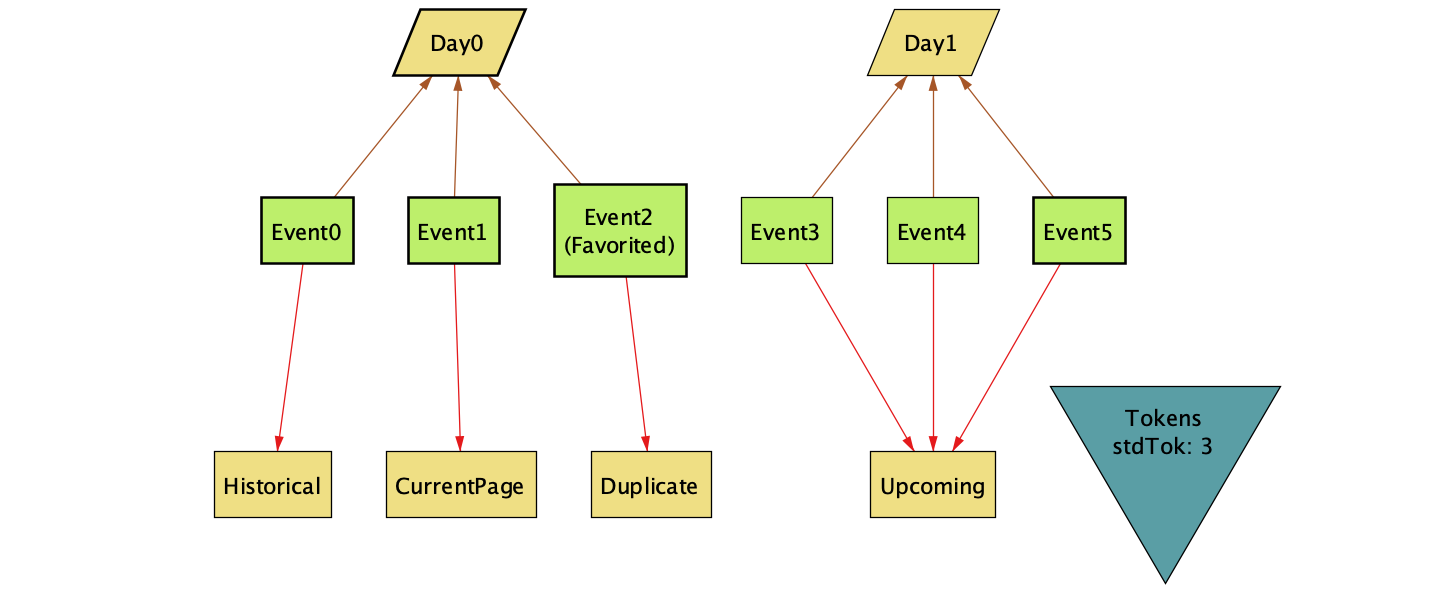
The visualizer is a tricky thing. It shows the state of all objects in the system and their relationships. The display is configurable — you can choose what to show and hide. Getting a clear view takes some fiddling, but stepping through a failing trace helps when debugging a counterexample.
Verification (AllEvents)
assert AllEvents_BaseCase {
initAllEvents[] implies inductiveInvariantAllEvents[]
}
assert AllEvents_InductiveStep {
always (
(inductiveInvariantAllEvents[] and loadMoreAllEvents[]) implies after inductiveInvariantAllEvents[]
)
}
assert AllEvents_Stutter {
always (
(inductiveInvariantAllEvents[] and stutter[]) implies after inductiveInvariantAllEvents[]
)
}
assert AllEvents_NoDuplicates {
traceAllEvents[] implies always (
all e: LastPageOutput |
not before (e in PriorEmitted)
)
}
assert AllEvents_Ordering {
traceAllEvents[] implies always orderingInvariant[]
}
assert AllEvents_Ordering_InductiveStep {
always (
(inductiveInvariantWithOrderingAllEvents[] and loadMoreAllEvents[]) implies after inductiveInvariantWithOrderingAllEvents[]
)
}
assert AllEvents_Liveness {
(traceAllEvents[] and always (some pageOutputAllEvents[Tokens.stdTok, Tokens.favTok] implies loadMoreAllEvents[]))
implies eventually (PriorEmitted = Event)
}Implementation B: ExcludeFavorites
The second approach excludes favorited events from the standard list. Favorites appear only in the favorited list. The two lists are disjoint.
fun stdListExcludeFav: Int -> Event {
{ position: Int, currentEvent: Event |
currentEvent not in Favorited and
position = #{otherEvent: Event | otherEvent not in Favorited and chronoBefore[otherEvent, currentEvent]} and
position >= 0 and position < #(Event - Favorited)
}
}
fun pageOutputExcludeFav[stdToken, favToken: lone Int]: set Event {
let stdCandidates = (no stdToken) => none
else stdListExcludeFav[{position: Int | position >= stdToken}],
favCandidates = (no favToken) => none
else favList[{position: Int | position >= favToken}],
candidates = stdCandidates + favCandidates |
{ event: candidates | #{otherEvent: candidates | mergeOrderBefore[otherEvent, event, favCandidates]} < Config.pageSize }
}
pred loadMoreExcludeFav[] {
let pageOutput = pageOutputExcludeFav[Tokens.stdTok, Tokens.favTok] {
some pageOutput
PriorEmitted' = PriorEmitted + pageOutput
LastPageOutput' = pageOutput
Tokens.stdTok' = advanceToken[stdListExcludeFav, Tokens.stdTok, pageOutput]
Tokens.favTok' = advanceToken[favList, Tokens.favTok, pageOutput]
}
}
pred initExcludeFav[] {
no PriorEmitted
no LastPageOutput
Tokens.stdTok = 0
Tokens.favTok = 0
}
pred traceExcludeFav[] {
initExcludeFav[]
always (loadMoreExcludeFav[] or stutter[])
}
pred inductiveInvariantExcludeFav[] {
inductiveInvariantGeneric[stdListExcludeFav]
}
pred inductiveInvariantWithOrderingExcludeFav[] {
inductiveInvariantWithOrderingGeneric[stdListExcludeFav]
}Why It Works
With disjoint lists, each event lives in exactly one source. When we emit a favorite from the favorited list, it doesn't exist in the standard list. No gap forms. Token advancement proceeds cleanly through each list, and no event can be fetched a second time from a different source.
The same invariant that AllEvents can't maintain, ExcludeFavorites maintains cleanly. Same proof structure, same auxiliary properties, different result.
Verification (ExcludeFavorites)
assert ExcludeFav_BaseCase {
initExcludeFav[] implies inductiveInvariantExcludeFav[]
}
assert ExcludeFav_InductiveStep {
always (
(inductiveInvariantExcludeFav[] and loadMoreExcludeFav[]) implies after inductiveInvariantExcludeFav[]
)
}
assert ExcludeFav_Stutter {
always (
(inductiveInvariantExcludeFav[] and stutter[]) implies after inductiveInvariantExcludeFav[]
)
}
assert ExcludeFav_NoDuplicates {
traceExcludeFav[] implies always (
all e: LastPageOutput |
not before (e in PriorEmitted)
)
}
assert ExcludeFav_Ordering_BaseCase {
initExcludeFav[] implies inductiveInvariantWithOrderingExcludeFav[]
}
assert ExcludeFav_Ordering_InductiveStep {
always (
(inductiveInvariantWithOrderingExcludeFav[] and loadMoreExcludeFav[]) implies after inductiveInvariantWithOrderingExcludeFav[]
)
}
assert ExcludeFav_Ordering_Stutter {
always (
(inductiveInvariantWithOrderingExcludeFav[] and stutter[]) implies after inductiveInvariantWithOrderingExcludeFav[]
)
}
assert ExcludeFav_Liveness {
(traceExcludeFav[] and always (some pageOutputExcludeFav[Tokens.stdTok, Tokens.favTok] implies loadMoreExcludeFav[]))
implies eventually (PriorEmitted = Event)
}Results
// === AllEvents (expect failures) ===
check AllEvents_BaseCase for 6 Event, 3 Day, 6 Int, 1 steps
check AllEvents_InductiveStep for 6 Event, 3 Day, 6 Int, 2 steps
check AllEvents_Stutter for 6 Event, 3 Day, 6 Int, 2 steps
check AllEvents_NoDuplicates for 6 Event, 3 Day, 6 Int, 6 steps
check AllEvents_Ordering for 6 Event, 3 Day, 6 Int, 5 steps
check AllEvents_Ordering_InductiveStep for 6 Event, 3 Day, 6 Int, 2 steps
check AllEvents_Liveness for 6 Event, 3 Day, 6 Int, 6 steps
// === ExcludeFavorites (expect all pass) ===
check ExcludeFav_BaseCase for 6 Event, 3 Day, 6 Int, 1 steps
check ExcludeFav_InductiveStep for 6 Event, 3 Day, 6 Int, 2 steps
check ExcludeFav_Stutter for 6 Event, 3 Day, 6 Int, 2 steps
check ExcludeFav_NoDuplicates for 6 Event, 3 Day, 6 Int, 6 steps
check ExcludeFav_Ordering_BaseCase for 6 Event, 3 Day, 6 Int, 1 steps
check ExcludeFav_Ordering_InductiveStep for 6 Event, 3 Day, 6 Int, 2 steps
check ExcludeFav_Ordering_Stutter for 6 Event, 3 Day, 6 Int, 2 steps
check ExcludeFav_Liveness for 6 Event, 3 Day, 6 Int, 6 steps
// === Example traces (open in Alloy visualizer) ===
run AllEvents_DuplicateTrace { interestingScenarios[] and traceAllEvents[] and eventually (some e: LastPageOutput | before (e in PriorEmitted)) } for 6 Event, 3 Day, 6 Int, 6 steps
run ExcludeFav_FullTrace { interestingScenarios[] and traceExcludeFav[] and eventually (no Tokens.stdTok and no Tokens.favTok) } for 6 Event, 3 Day, 6 Int, 6 stepsIn Alloy, check asks whether a counterexample to an assertion exists within the given scope. UNSAT (unsatisfiable) means no counterexample was found — the assertion holds. SAT (satisfiable) means a counterexample exists — the assertion is violated. This is counterintuitive: SAT is the bad result.
Running alloy6 exec of-faults-and-favorites.md produces:
00. check AllEvents_BaseCase UNSAT
01. check AllEvents_InductiveStep SAT ← invariant breaks
02. check AllEvents_Stutter UNSAT
03. check AllEvents_NoDuplicates SAT ← duplicates found
04. check AllEvents_Ordering UNSAT
05. check AllEvents_Ordering_InductiveStep SAT ← ordering breaks too
06. check AllEvents_Liveness UNSAT ← but it still completes
07. check ExcludeFav_BaseCase UNSAT
08. check ExcludeFav_InductiveStep UNSAT ← invariant holds
09. check ExcludeFav_Stutter UNSAT
10. check ExcludeFav_NoDuplicates UNSAT ← no duplicates
11. check ExcludeFav_Ordering_BaseCase UNSAT
12. check ExcludeFav_Ordering_InductiveStep UNSAT ← ordering proved
13. check ExcludeFav_Ordering_Stutter UNSAT
14. check ExcludeFav_Liveness UNSAT ← all events emitted
15. run AllEvents_DuplicateTrace SAT ← trace with duplicate
16. run ExcludeFav_FullTrace SAT ← complete pagination traceThe three SAT results for AllEvents are the key findings. Note that AllEvents_Liveness passes — the algorithm completes and emits every event. It just emits some of them twice. Liveness without correctness.
- AllEvents_InductiveStep: SAT means Alloy found a state where the invariant holds, but after one
loadMoretransition it breaks. The algorithm cannot maintain the strengthened invariant when the lists overlap. This is the inductive proof that the design is broken at any scale. - AllEvents_NoDuplicates: SAT means Alloy found a concrete trace where the same event appears in
LastPageOutputwhen already inPriorEmitted. This is the bounded proof that duplicates actually happen. - AllEvents_Ordering_InductiveStep: SAT means the ordering invariant also cannot be maintained inductively. The overlap between lists lets the standard list emit events on a day before the favorites list delivers all favorites for that day.
Every ExcludeFavorites check returns UNSAT. The bounded checks (like NoDuplicates) confirm no violations exist within the given scope of 6 events and 3 days. The inductive checks go further: the base case plus inductive step together prove the properties hold in all reachable states, for any event count, day count, page size, or trace length. Induction doesn't depend on scope — if the invariant holds across one arbitrary transition, it holds across all.
ExcludeFav_Liveness adds a final piece: under a fairness constraint (the algorithm always makes progress when it can), every event is eventually emitted. This confirms the algorithm doesn't just avoid bugs — it actually completes.
The two run commands produce concrete traces you can step through in the Alloy visualizer. AllEvents_DuplicateTrace shows a trace where a duplicate occurs. ExcludeFav_FullTrace shows a complete pagination run from start to finish.
Conclusion
Testing tells you "we checked these cases and they passed." Model checking tells you "this property holds for every reachable state." And when a design is broken, you don't get a bug report — you get proof the design can't hold the property at any scale.
The practical barrier has always been the learning curve. TLA+ and Alloy require a different kind of thinking and an understanding of some unfamiliar syntax. Leveraging LLMs allows us to ease into the syntax and concepts, while focusing on the logic.
Not every algorithm needs formal verification. But when subtle interactions between components can produce bugs that testing won't catch until production, a model checker is the right tool. The hard part is unchanged: you need to understand your problem well enough to confirm the checker is checking what you intend.